Translations: Japanese/日本語 🇯🇵, Korean/한국어 🇰🇷
p2p live streaming with hypervision
Live streaming is really fun. Now that it exists on almost every major social networking service, it's as easy to broadcast something live from your camera as it is to share a photo of it.
Being able to deliver live audio and video to thousands of viewers at a time takes a lot of bandwidth. If you ran a server that needed to push a video stream with some degree of quality to 100 viewers, you'd probably be pushing around 40-50GB of data every hour. This kind of data transfer also relies on a connection that can deal with a high level of throughput, something most consumer internet connections cannot handle.
While broadcasting through YouTube or Facebook is relatively simple, I'm far more excited about what a future decentralised internet looks like. If we could broadcast with peer-to-peer technology, bypassing restrictive social networks in favour of something open, accessible, and censorship-free would be easy.
As a weekend project, I decided to dive into the source code for hypervision, an experimental codebase that bills itself simply as "P2P television". I wanted to understand what it does, and try making some contributions in return.
What is hypervision?
hypervision is a desktop application that lets you both watch and broadcast peer-to-peer live streams. When users connect to a stream, they distribute the data they receive amongst each other. This bypasses the need for a central server, and the huge amount of bandwidth required to deliver the same data to every user.
hypervision was started by Mathias Buus, a developer from the Dat Project. Much of the technology hypervision relies on forms the basis of Dat.
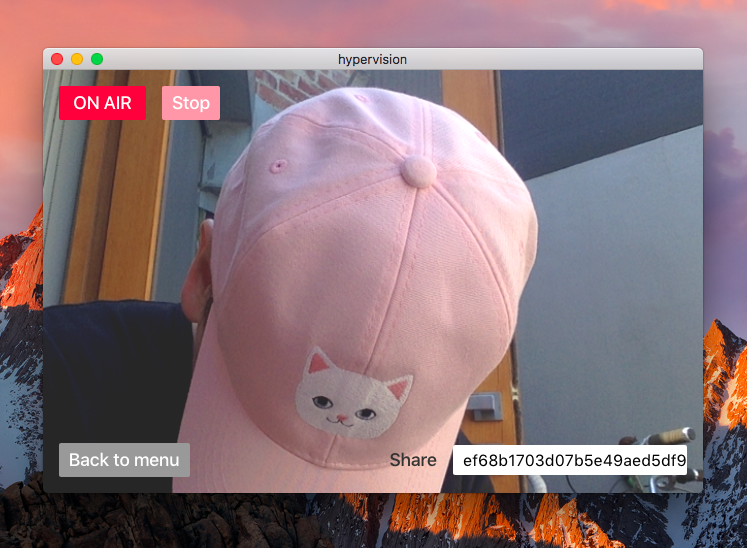
How does it work?
hypervision is built on top of a handful of JavaScript modules, the two most interesting being hypercore and hyperdiscovery.
hypercore is a type of data storage that can be easily redistributed to other computers. Its intended purpose is to make sharing large datasets and streams of real-time data very trivial.
hyperdiscovery allows hypercore feeds to be discovered by other users. When a feed is passed in, hyperdiscovery goes looking for other users who want that same data. This is very similar to the way BitTorrent users connect to other peers.
Before we start broadcasting, hypervision connects to any media devices (like cameras or microphones) that are attached to the user's computer. As hypervision is built with Electron, a desktop application framework built on top of the Chrome browser, we can access these devices using the getUserMedia() API.
var recorder = require('media-recorder-stream')
var cluster = require('webm-cluster-stream')
navigator.webkitGetUserMedia({
audio: true,
video: true
}, function (media) {
var stream = recorder(media, { interval: 1000 }).pipe(cluster())
})When we initialise one of these devices, we get back a media stream in return. After a few more steps, this data eventually ends up as a collection of .webm format video buffers, broken down into small pieces.
When any new data is received from our camera or microphone, we add this to our hypercore feed as a small buffer.
var hypercore = require('hypercore')
var level = require('level')
var swarm = require('hyperdiscovery')
var core = hypercore(level('producer.db'))
var feed = core.createFeed({
storage: raf('producer.data/' + Date.now() + '.feed')
})
swarm(feed)At this point, the feed has been passed into hyperdiscovery, and our real-time data is then made available to any other users looking for it. This "swarm" of users then share around any of the buffers that other users want.
When we create a new feed using hypercore, we receive back a key that can be shared with other users that want to connect to our stream. This key becomes the identifier for our broadcast on the p2p network.
var key = feed.key.toString('hex')As a viewer, when we enter in a key, we go looking for others users who can share the stream data that we want. This process also happens through hyperdiscovery. When we start receiving data, we begin adding each buffer to a new hypercore feed.
var core = hypercore(level('viewer.db'))
var feed = core.createFeed(key, {
sparse: true,
storage: raf('viewer.data/' + key + '.feed')
})On the screen, we tell a <video> element to begin watching the .webm video that hypervision has been piecing together. At this point, we have now tuned into the broadcast, while simultaneously distributing the same broadcast to other viewers.
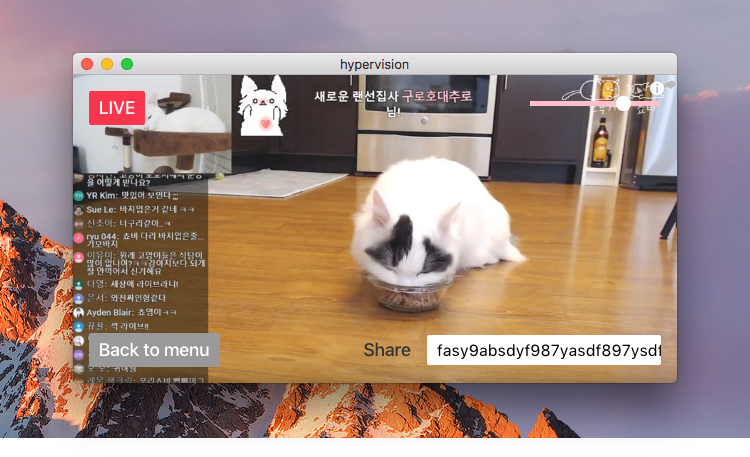
Contributing to hypervision
Prior to writing this, hypervision was essentially an application with no user interface. By digging into its source code to understand how it works, I was then able to cut a simple UI together, making navigation easier for first time users. I also added features like device previewing, bitrate selection, and the ability for broadcasters to switch between their webcam and screen sharing.
I have submitted a PR to hypervision which includes all of these updates. Until this is merged, you can play around with the new UI by cloning louiscenter/hypervision and following the build instructions in the README.
Update: The PR I submitted has now been merged. You can play around with the new UI by heading to hypervision's GitHub repository and following the instructions in README.md.
What next for hypervision?
As hypervision is an open source JavaScript project, it's easy for anyone who is comfortable writing code for Node.js or the browser to jump in and start building new features.
One thing I'd like to do is remove hypervision's reliance on having to read and write hypercore feeds to the user's filesystem, and then swarm that data using WebRTC. By doing this, users would be able to watch and broadcast p2p live streams simply by visiting a website in their browser, rather than having to download an entire desktop application.
By making peer-to-peer live streaming in the browser easy to access and use, it then becomes a viable alternative to other centralised streaming platforms.